Python Streamlit을 활용한 Parquet 파일 데이터 시각화와 필터링 기능 구현
Streamlit을 활용한 Parquet 파일 데이터 시각화와 필터링 기능 구현
파이썬은 데이터 과학 및 웹 애플리케이션 개발에 강력한 도구로 널리 사용됩니다. 그중에서도 Streamlit은 간단한 코드로 데이터 시각화와 인터랙티브 대시보드를 구축할 수 있어 데이터 분석가와 개발자들에게 많은 사랑을 받고 있습니다. 이번 글에서는 Streamlit을 활용해 Parquet 파일 데이터를 읽고, 필터링, 그룹화(GroupBy), 차트 시각화 기능을 구현하는 방법을 소개합니다.
Parquet 파일이란?
Parquet 파일은 Apache Parquet에서 제공하는 열 기반 스토리지 포맷입니다. CSV와 같은 행 기반 포맷보다 데이터 압축과 쿼리 성능에서 더 우수한 효율을 제공합니다. 대용량 데이터 처리와 저장에 적합하기 때문에, 데이터 분석 및 머신러닝에서 널리 사용됩니다.
파이썬에서는 pandas 라이브러리를 활용해 Parquet 파일을 손쉽게 읽고 쓸 수 있습니다. 예제를 진행하기 위해 pyarrow를 설치해야 하며, 다음 명령어를 사용합니다.
pip install pandas pyarrow streamlit
Streamlit으로 데이터 시각화 앱 만들기
이제 Parquet 데이터를 읽고 Streamlit으로 시각화하는 앱을 단계별로 만들어보겠습니다.
1. Parquet 파일 읽기
먼저 Parquet 파일을 읽고 데이터를 데이터프레임 형태로 로드합니다. 여기서는 Streamlit 앱에서 데이터를 시각화할 준비를 합니다.
다음과 같이 Parquet 파일을 불러오는 코드를 작성할 수 있습니다.
import pandas as pd
import streamlit as st
# Parquet 파일 경로
file_path = 'D:\\test\\DEMAND.parquet'
# Parquet 파일 읽기
df = pd.read_parquet(file_path, engine='pyarrow')
# Streamlit 앱 제목
st.title("Parquet 파일 데이터 시각화")
st.dataframe(df) # 데이터 출력
이 코드를 실행하면 Parquet 데이터가 Streamlit의 기본 데이터 그리드 형식으로 출력됩니다. 데이터를 한눈에 확인할 수 있어 매우 편리합니다.
2. 필터링 기능 구현
Streamlit은 사이드바와 상호작용 위젯을 제공하여 사용자 입력을 받을 수 있습니다. 이 예제에서는 날짜 범위 필터링을 추가합니다. 데이터프레임에서 DUE_DATE 열을 기준으로 사용자가 범위를 선택하면, 선택된 데이터만 화면에 표시됩니다.
# 사이드바 필터링 옵션
st.sidebar.header("필터링 옵션")
date_min = df['DUE_DATE'].min()
date_max = df['DUE_DATE'].max()
# 날짜 범위 필터링
selected_dates = st.sidebar.date_input(
"날짜 범위 선택",
value=(date_min, date_max),
min_value=date_min,
max_value=date_max
)
# 필터링된 데이터
filtered_df = df[
(df['DUE_DATE'] >= pd.to_datetime(selected_dates[0])) &
(df['DUE_DATE'] <= pd.to_datetime(selected_dates[1]))
]
st.dataframe(filtered_df)
이 코드는 사이드바에서 날짜 범위를 선택할 수 있도록 하고, 선택한 범위에 해당하는 데이터만 화면에 출력합니다.
3. GroupBy로 데이터 요약
GroupBy는 데이터를 그룹화하여 특정 열의 집계를 계산하는 데 유용합니다. 이 예제에서는 DUE_DATE를 기준으로 데이터를 그룹화하고 DEMAND_QTY의 합계를 계산합니다.
# GroupBy 적용
grouped_df = filtered_df.groupby("DUE_DATE", as_index=False)["DEMAND_QTY"].sum()
st.subheader("GroupBy 데이터")
st.dataframe(grouped_df)4. 차트로 데이터 시각화
Streamlit은 차트를 출력하는 여러 함수를 제공합니다. 여기서는 st.line_chart를 사용해 DUE_DATE별 DEMAND_QTY의 합계를 시각화합니다.
if 'DEMAND_QTY' in grouped_df.columns and 'DUE_DATE' in grouped_df.columns:
st.subheader("DEMAND_QTY 시각화")
st.line_chart(grouped_df.set_index('DUE_DATE')['DEMAND_QTY'])
이 코드는 grouped_df 데이터를 기반으로 라인 차트를 출력하며, 날짜별 수요량을 한눈에 확인할 수 있습니다.
5. 데이터와 차트를 접고 펼치기
Streamlit의 st.expander를 사용하면 데이터를 접거나 펼칠 수 있습니다. 이를 통해 앱의 사용자 인터페이스를 깔끔하게 유지할 수 있습니다.
# 원본 데이터 보기
with st.expander("원본 데이터 보기", expanded=True):
st.dataframe(df)
# GroupBy 데이터 보기
with st.expander("GroupBy 데이터 보기", expanded=False):
st.dataframe(grouped_df)
# 차트 시각화 보기
with st.expander("DEMAND_QTY 시각화", expanded=True):
st.line_chart(grouped_df.set_index('DUE_DATE')['DEMAND_QTY'])코드 전체
위 기능을 모두 통합한 최종 코드는 다음과 같습니다.
import streamlit as st
import pandas as pd
# Parquet 파일 경로
file_path = 'D:\\test\\DEMAND.parquet'
# Parquet 파일 읽기
df = pd.read_parquet(file_path, engine='pyarrow')
st.title("Parquet 파일 데이터 시각화")
# 데이터 접기/펼치기
with st.expander("원본 데이터 보기", expanded=True):
st.dataframe(df)
# 사이드바 필터링
st.sidebar.header("필터링 옵션")
date_min = df['DUE_DATE'].min()
date_max = df['DUE_DATE'].max()
selected_dates = st.sidebar.date_input(
"날짜 범위 선택",
value=(date_min, date_max),
min_value=date_min,
max_value=date_max
)
filtered_df = df[
(df['DUE_DATE'] >= pd.to_datetime(selected_dates[0])) &
(df['DUE_DATE'] <= pd.to_datetime(selected_dates[1]))
]
# GroupBy 데이터
grouped_df = filtered_df.groupby("DUE_DATE", as_index=False)["DEMAND_QTY"].sum()
with st.expander("GroupBy 데이터 보기", expanded=False):
st.dataframe(grouped_df)
# 차트 시각화
with st.expander("DEMAND_QTY 시각화", expanded=True):
st.line_chart(grouped_df.set_index('DUE_DATE')['DEMAND_QTY'])실행 결과 화면
위 코드를 기반으로 실행한 화면은 다음과 같습니다.
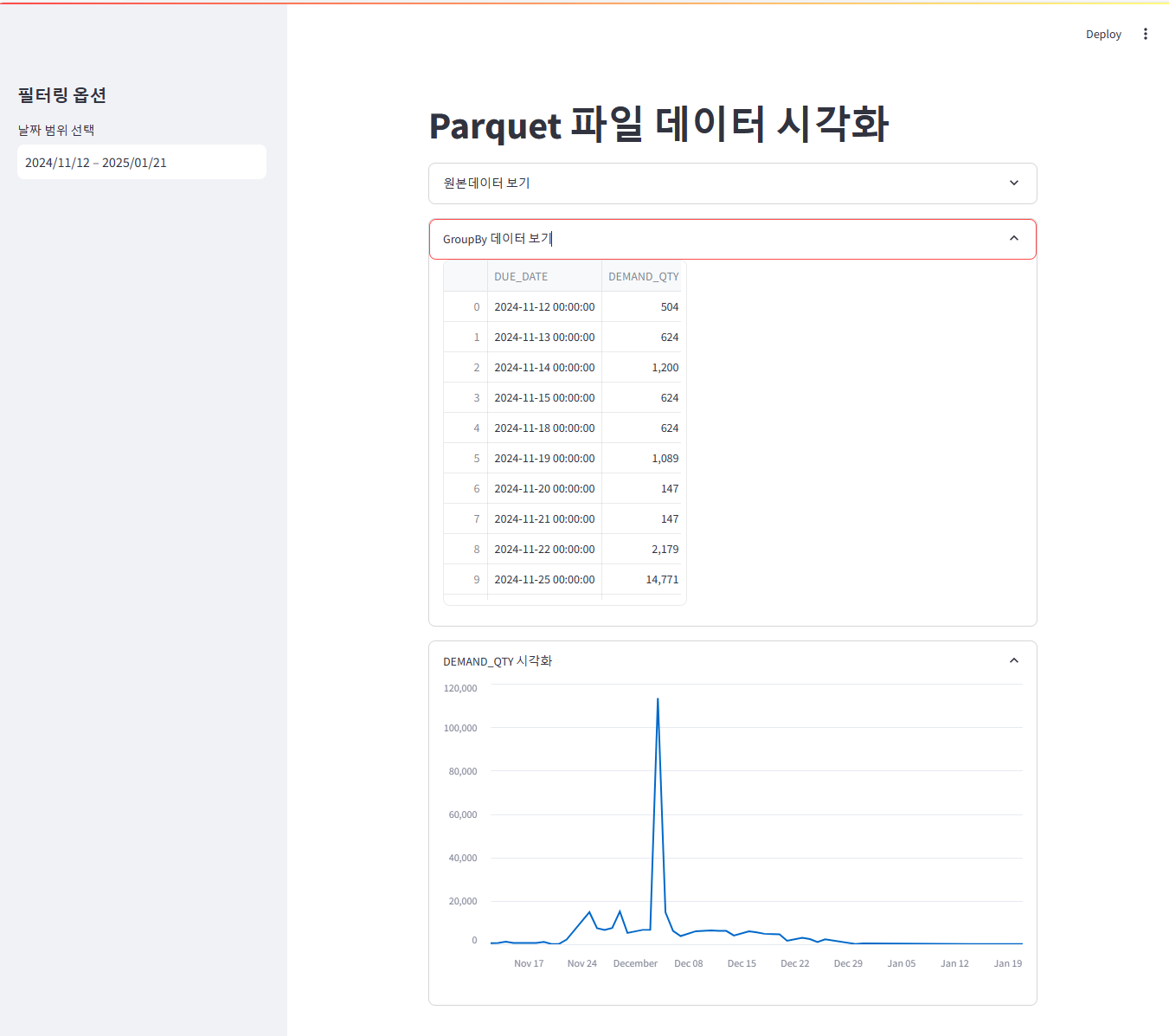
결론
이 예제에서는 Streamlit을 활용해 Parquet 데이터를 읽고, 필터링, 그룹화, 차트 시각화를 구현하는 방법을 소개했습니다. 이와 같은 방법으로 데이터 분석과 대시보드를 쉽게 구축할 수 있습니다.